LoopLess
Student-founded productivity startup • iOS + behavioral science
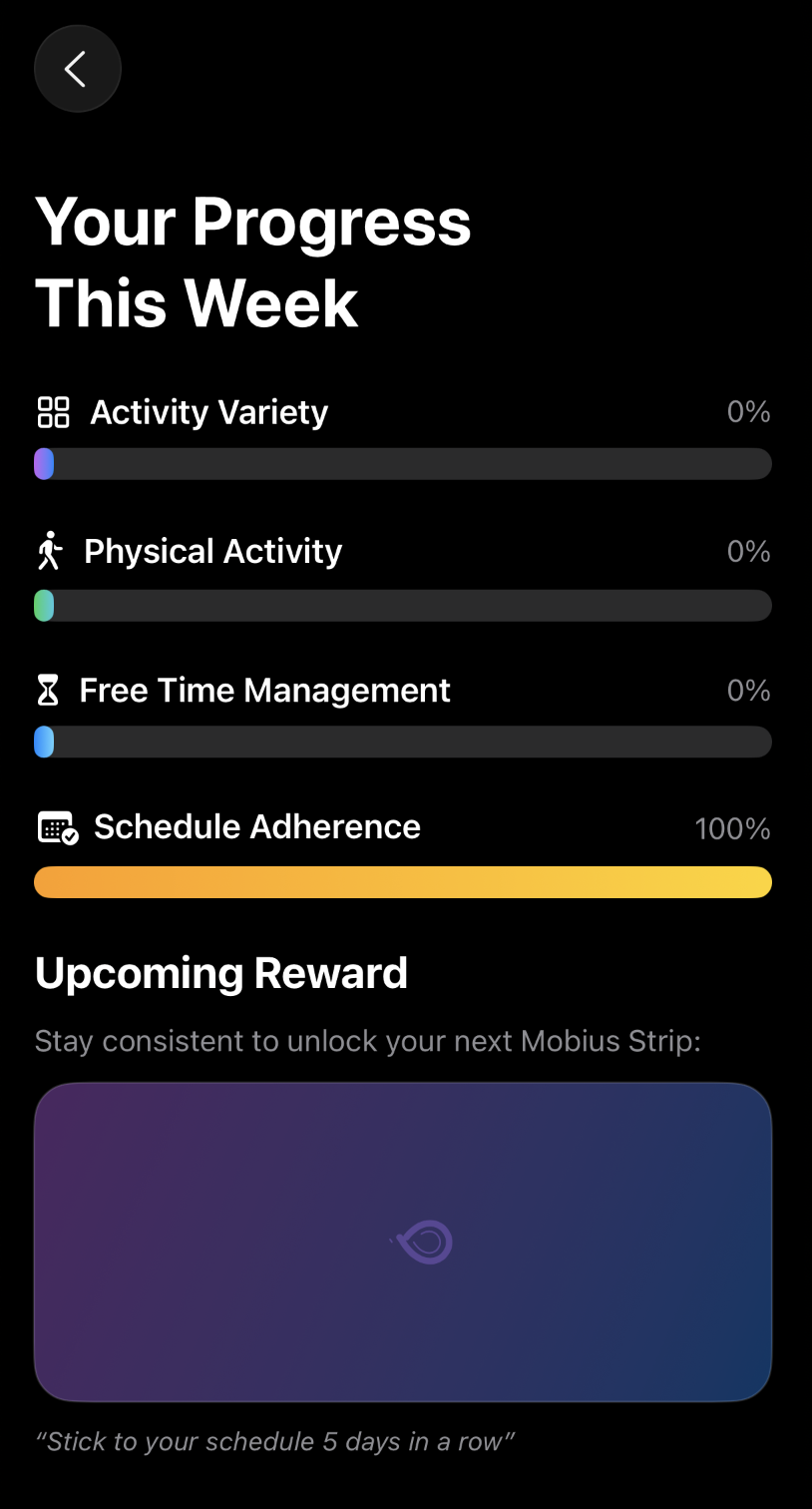
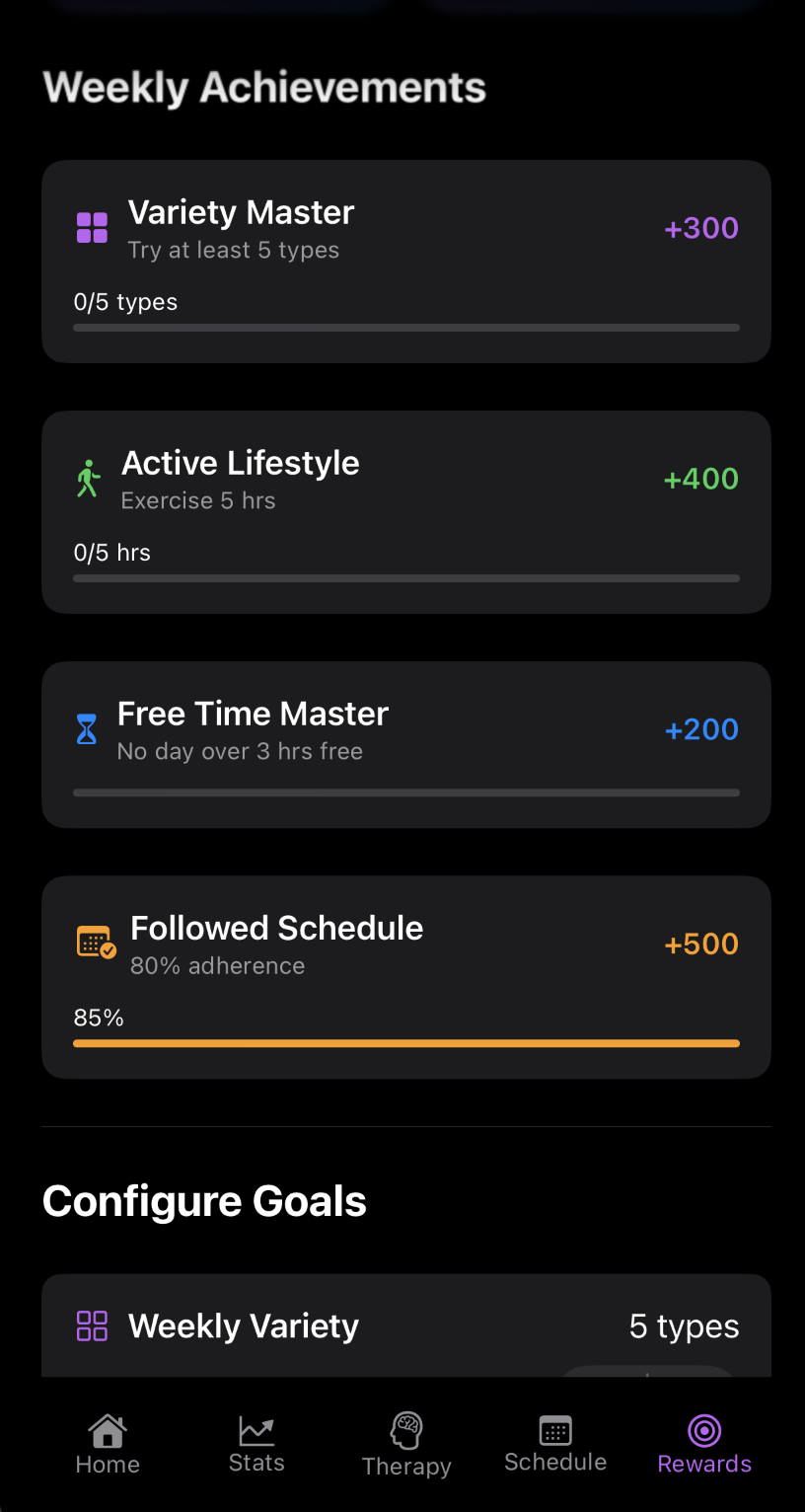
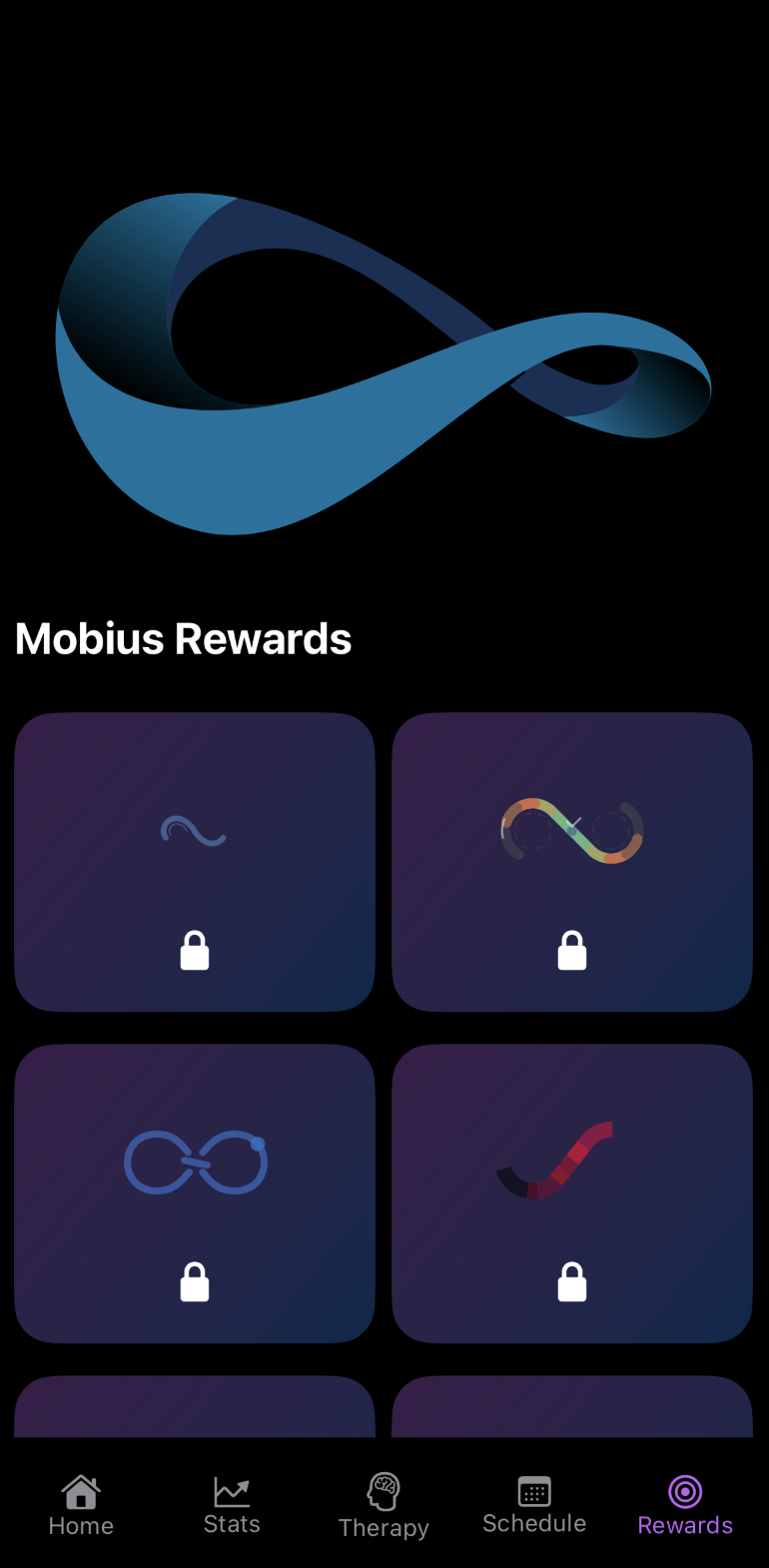
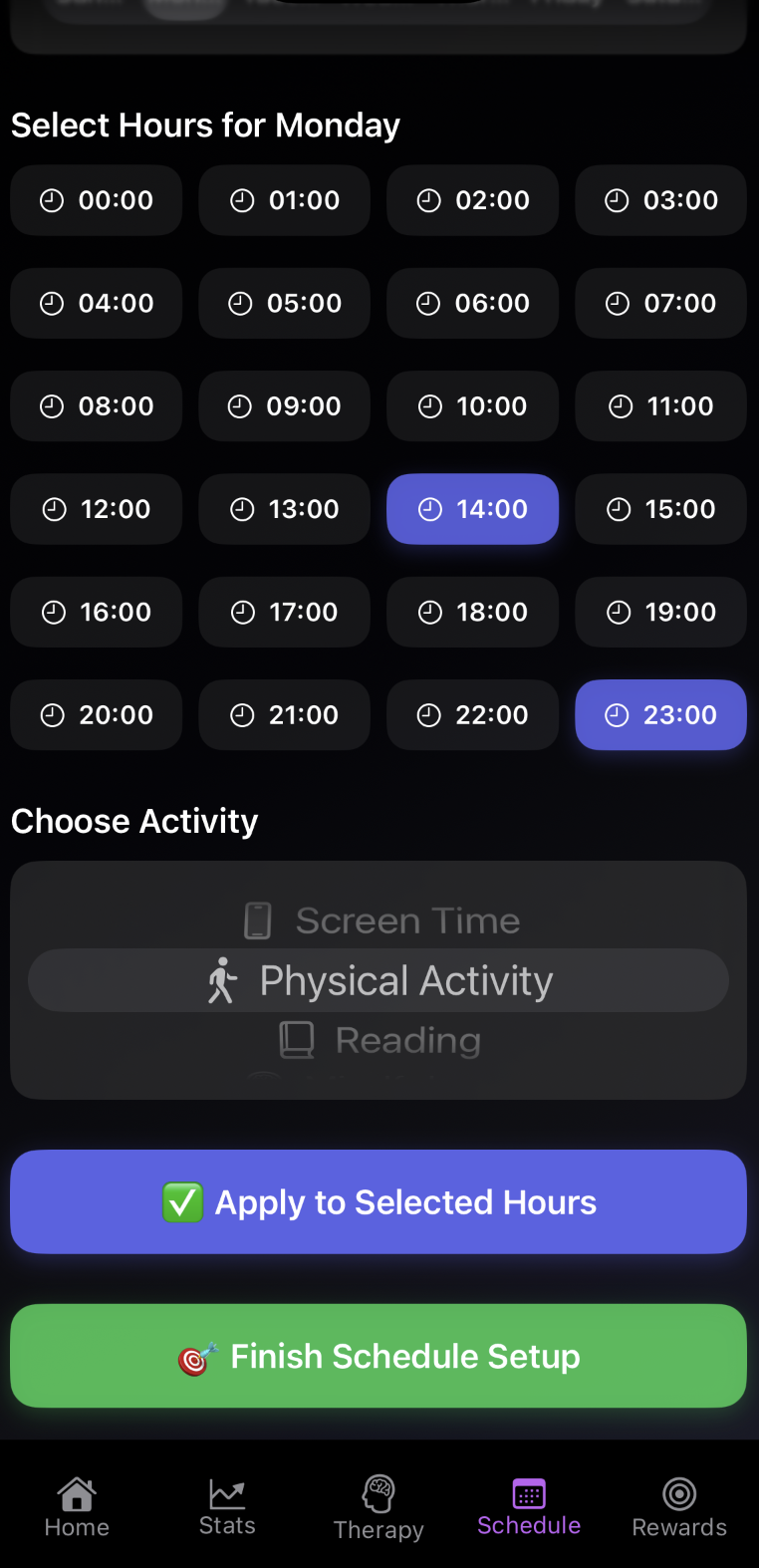
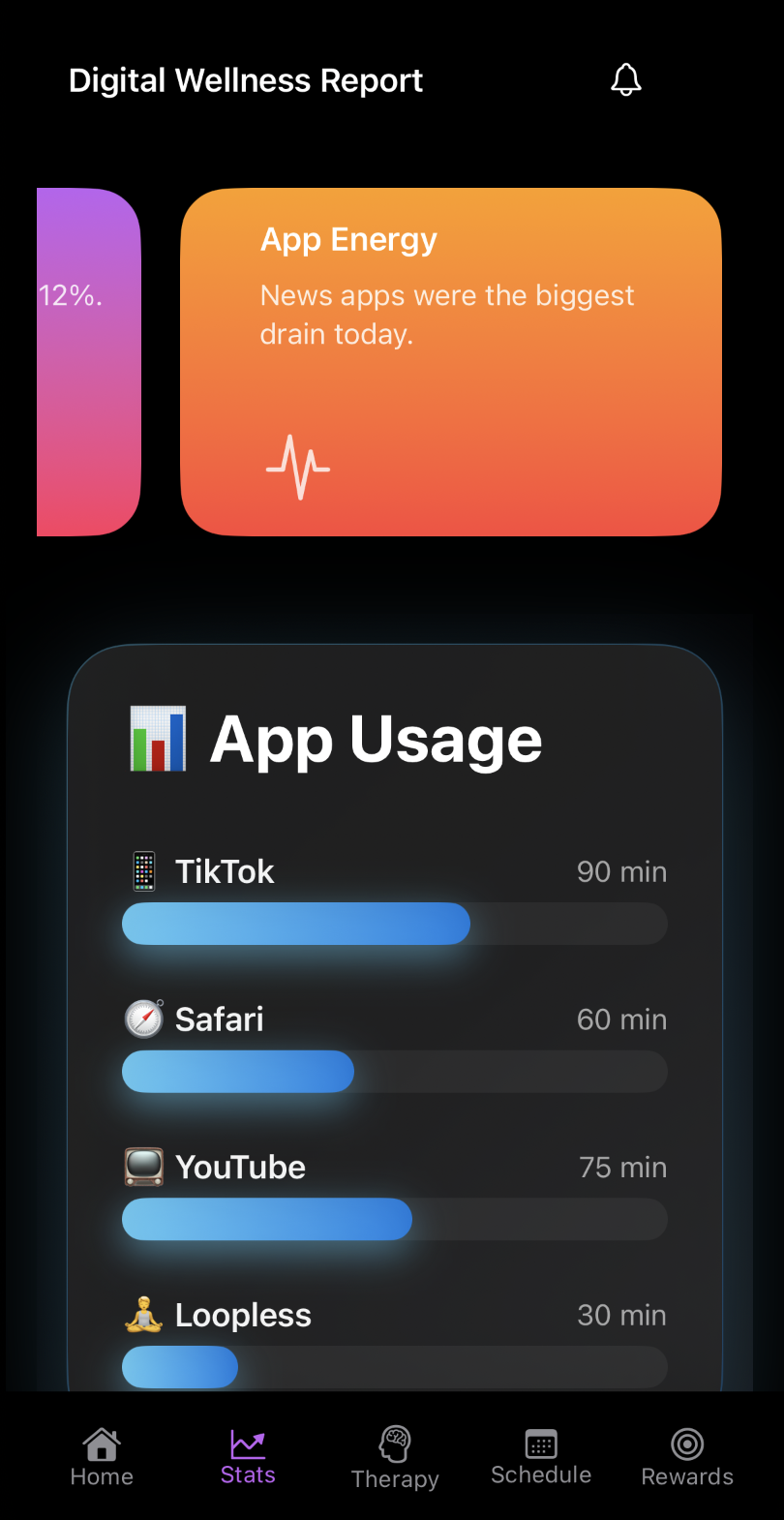
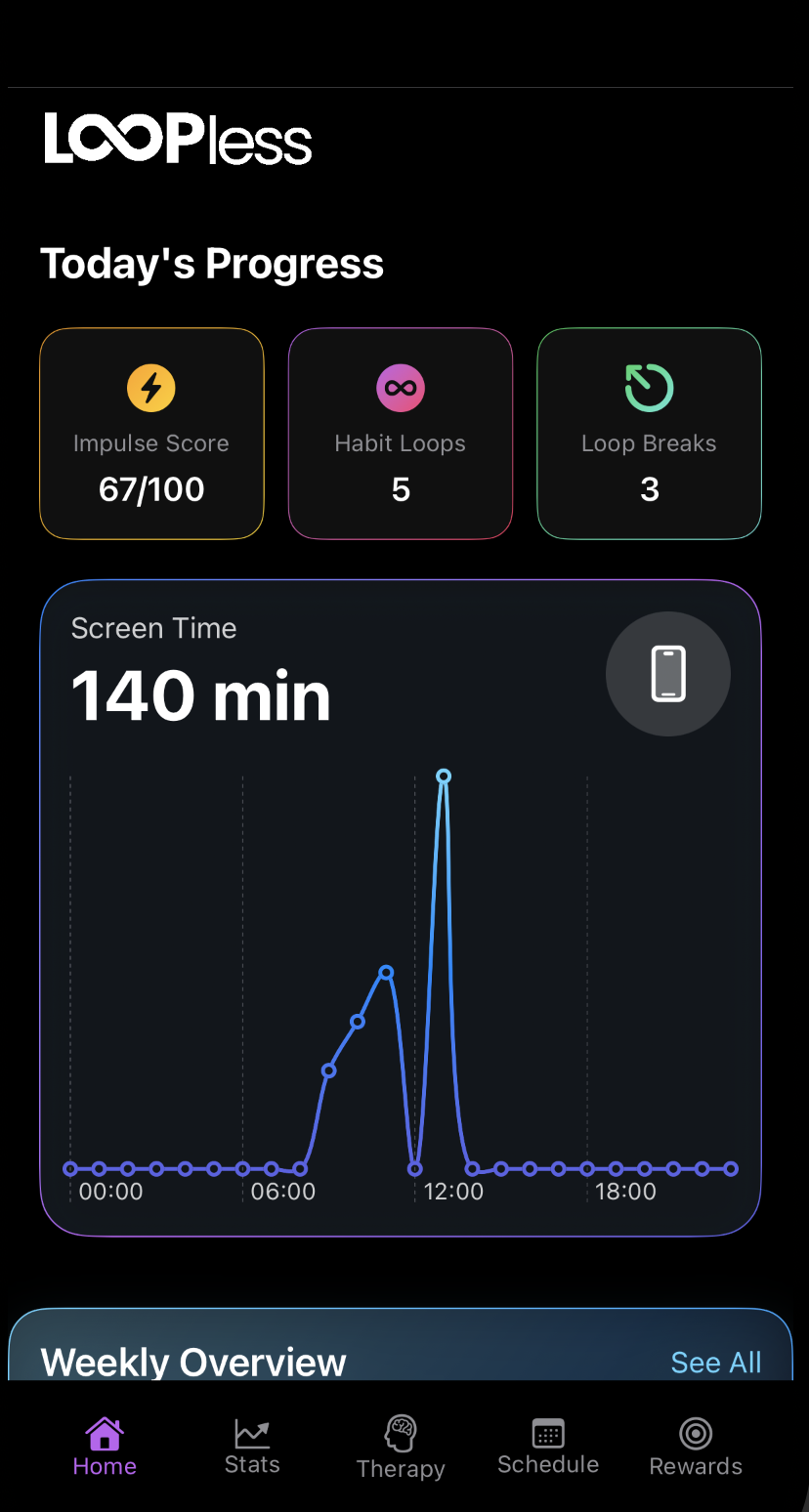
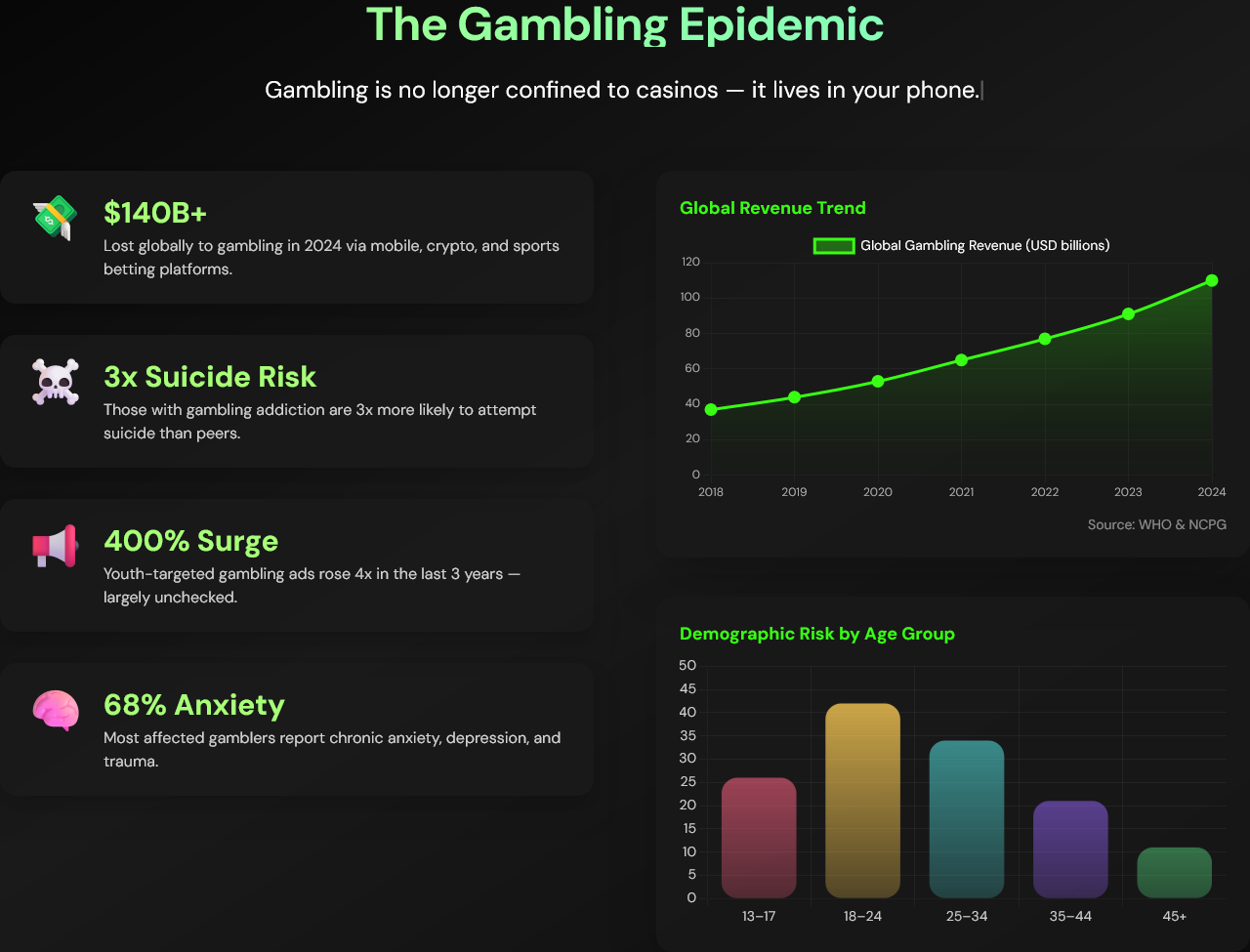
LoopLess is a student-founded productivity startup on a mission to help people break the endless scroll and live with intent. I built an iOS app that blends CBT concepts, mindfulness science, and structured reflection into a focused, modern experience, a personal “focus trainer” that nudges you toward healthier digital routines.